YepAPI
综合介绍
YepAPI 是一款专为开发者和 AI 智能体打造的统一 API 聚合服务平台。它打破了传统开发中需要同时对接不同服务商的繁琐流程,仅需一个统一的 API 密钥,即可无缝调用网页全功能抓取、SEO 数据分析、搜索引擎结果页(SERP)拉取以及对各主流社交媒体(YouTube、TikTok、Instagram)的深度数据提取。不仅如此,平台更是集成了一个兼容主流协议的统一 AI 大模型网关,涵盖超过 60 种前沿大语言模型(如 GPT-5.4、Claude Opus 4.6、DeepSeek V3.2 等)以及音视频多模态生成模型(如 Sora 2、Nano Banana 3)。YepAPI 彻底摈弃了复杂的订阅费用,采用纯正的“按次调用付费(Pay-per-call)”模式,没有最低消费与强制订阅。通过对 llms.txt 和 MCP(Model Context Protocol)协议的原生支持,它还能与 Cursor、Claude 等 AI 开发助手完美融合,是当今开发现代化 AI 应用的高效基建。
功能列表
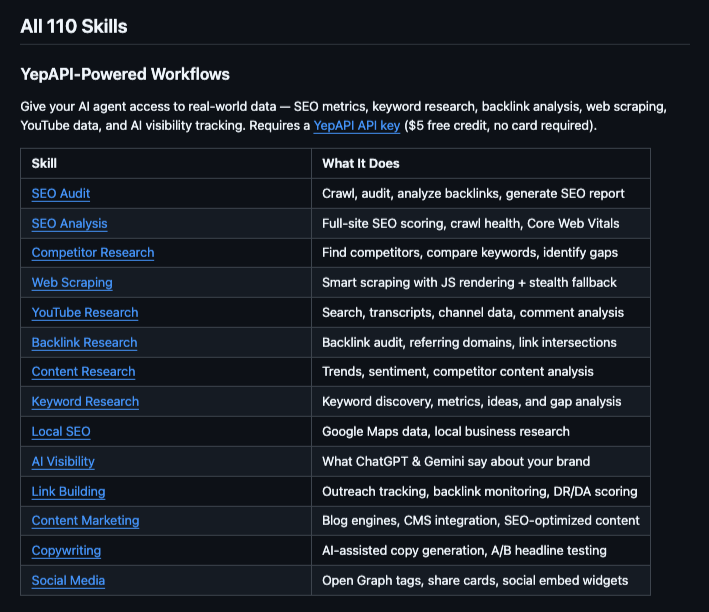
- 动态网页智能抓取 (Web Scraping):提供 12 个端点,支持 JavaScript 动态页面渲染、自动突破验证机制的深度抓取、网页全尺寸截图获取,以及结合大语言模型的非结构化数据提炼。完美支持单页应用(SPA)和需登录页面的数据采撷。
- 统一 AI 聚合接口 (AI Models API):提供 60 多个模型的一键调用,包括最新版 GPT-5.4、Claude 4.6 系列、Gemini 3.1 Pro、DeepSeek V3.2 等大语言模型,全面兼容 OpenAI 的 API 请求格式。
- 多模态媒体生成服务 (Media Generation):原生接入 Sora 2 视频生成大模型、Nano Banana 3 高质量图像生成以及 Lyria 3 音乐音频生成,支持多种分辨率及并发处理。
- 全系社交平台深度数据读取:涵盖针对 YouTube(23 个端点)、TikTok(18 个端点)和 Instagram(15 个端点)的数据挖掘工具,支持批量调取用户画像、发文列表、视频元数据与评论互动记录。
- SEO 与搜索引擎情报挖掘 (SEO & SERP):支持获取全网精准的搜索引擎结果(包括谷歌、亚马逊)、关键词热度监控、网站反向链接追踪,以及多维度域名权威度(Domain Authority)剖析。
- AI 品牌可见度监测 (AI Visibility):提供专有端点分析 ChatGPT、Claude 等大模型在输出结果时对于特定品牌、产品的提及频率与引荐效果,帮助企业掌握在“AI搜索引擎”时代的品牌曝光度。
- 智能体自动化生态集成 (MCP Ready):直接提供标准的
llms.txt配置文件和 MCP 服务器集成能力,支持主流基于 LLM 的 Vibe Coding 工具零代码解析接入。
使用帮助
YepAPI 的核心理念是“极简调用、所见即所得”。无论是传统全栈应用还是新兴的基于 AI 的智能体,都能通过高度一致的数据标准迅速上手。以下是系统且详细的操作和安装使用流程。
一、 账号注册与 API 密钥的获取
- 账号创建:访问 YepAPI 官网,点击右上角的“Get Started”进行快速注册。整个流程无需绑定信用卡或其他支付方式。
- 领取初始额度:注册成功后,新用户可直接获得 5 美元的免费积分(Free Credit),这足以支撑测试成百上千次常规的 API 拉取。
- 获取 API 密钥:在用户的账户仪表盘(Dashboard)中,你将看到一个以
yep_sk_开头的密钥字符串。这不仅是你在 YepAPI 的唯一身份标识,也是驱动后台 130 多个不同端点的“万能钥匙”。请务必将该密钥妥善保存在你的环境变量.env中,切勿在前端代码中暴露。
二、 HTTP / RESTful 接口通用请求规范
YepAPI 中的不同功能模块统一共用一套极度精简的 HTTP POST 标准,所有的请求都不再需要安装冗杂的各家专用 SDK。只要掌握一种请求格式,即可通吃全站接口。
请求认证说明:所有的 API 调用都要求在 HTTP Header 的 Authorization 中以 Bearer Token 形式传入你的统一 API 密钥,并将数据交互格式 Content-Type 设为 application/json。
实战演示:基础网页全能抓取若你需要突破反爬虫机制,抓取某个页面的 Markdown 格式内容,请执行以下命令:
curl -X POST https://api.yepapi.com/v1/scrape \
-H "Authorization: Bearer yep_sk_your_key" \
-H "Content-Type: application/json" \
-d '{"url": "https://example.com", "format": "markdown"}'
标准化返回结构解读:返回对象中包含两部分关键信息:
data: 包含执行结果(如上文提取出的 markdown 正文文本、网页标题等)。credits: 显示本次调用所消耗的点数(used)以及账户内的实时剩余点数(remaining)。这极大地便利了开发者实时掌控财务消耗状况。
三、 AI 智能编程助手与智能体(Agent)自动化接入指南
YepAPI 对于现代化开发工具拥有现象级的支持。你可以直接将 YepAPI 嵌入到诸如 Cursor、Claude Desktop、Codex 或任何具备 MCP(Model Context Protocol)规范的智能体中。
操作步骤如下:
- 获取描述文档配置:YepAPI 提供了专属于大模型的路由地图表——
llms.txt。只需要在你的 AI 助手的 Prompt 中粘贴指令:“I want to use YepAPI's API endpoints to build an app. Check their offerings and docs here:https://docs.yepapi.com/llms.txt”。 - AI 自主学习 API:发送上述指令后,你的大模型会瞬间读取整个
llms.txt和llms-full.txt文件,它会自动理解所有 130+ 个接口的请求参数规则。 - 对话式编写集成代码:接下来你只需向 AI 助手描述诉求:“写一个脚本,利用 YepAPI 查找关键词对应的竞品 YouTube 视频数据,并把结果发送给模型 DeepSeek V3.2 进行总结汇总。”AI 即可一步到位生成包含精准端点、正确鉴权和参数校验的成型代码。
四、 重点功能模块的高阶操作流程详解
1. 统一 AI 大语言模型切换操作
以往对接不同的模型,需要注册 Anthropic、OpenAI、DeepSeek 多个平台的开发者账号并分别调试格式。但在 YepAPI,所有的大语言模型接口完全兼容 OpenAI 原生的 /v1/chat/completions API 规范。
- 使用流程:使用任何标准 OpenAI 兼容的 HTTP 客户端包(如 Python 的
openai库)。 - Base URL 替换:将接口基础地址改为
https://api.yepapi.com/v1。 - 密钥替换:输入你的 YepAPI 统一密钥。
- 无缝切换参数:在模型(Model)字段中,直接输入目标模型名称(如
gpt-5.4,claude-opus-4.6,deepseek-v3.2)。代码几乎不需修改,即可完成模型的随意替换与 A/B 测试对比。
2. SEO 分析与 SERP 数据抓取操作
当开展竞争对手流量分析或是关键词规划分析时:
- 调用
v1/seo/keywords节点,传入目标关键词及区域限定,API 返回精准的自然搜索量(Search Volume)、关键词难度评估(KD)以及相关长尾关键词建议。 - 调用
v1/serp/google获取指定关键词下的自然排名链表、"People Also Ask" 模块以及 AI 自动概括(AI Overviews)的具体引用内容。由于实行“按调用次数(Pay per call)”策略(如 SEO 数据仅 $0.05/次),在极低的成本内即可自建完整的 SEO 监控仪盘表。
3. Sora 2 与多模态生成模型应用操作
在处理多媒体生成的业务逻辑时,采用特定专用的视频及图像终端点。例如调用 v1/media/video/sora-2:
- 请求配置:在请求体中附带文本提示词(Prompt),并根据应用需求设定生成时长(支持 4 到 20 秒)。
- 按秒计费处理机制:系统采取异步任务调配架构。视频生成可能耗费几秒至几分钟不等,你可以通过 Webhook 回调接收视频 CDN 链接。计费按生成的视频时长结算(例如从 $0.10/秒开始计费),最大程度规避资源的浪费。
五、 异常排查及费用防泄漏保护机制
平台内部拥有完善的安全护城河。
- 容错防扣费机制:如果某次网页抓取遇到硬性反爬虫防御导致响应失败,或是请求某个 AI 模型出现服务端报错,系统绝不会针对此失败请求扣除积分(Credits)。
- 并发扩展(Scaling):如果你的企业业务需要并发数千次请求,YepAPI 虽然没有强硬的硬性频率限制(Rate limit),但在大量并发时,建议结合异步请求处理池进行缓冲。遇到任何 429 或 502 状态码,由于未发生实质扣费,程序仅需做延迟重试即可恢复流程稳定。
应用场景
- 智能数据采集与分析自动化面板系统借助 YepAPI 的 SEO 端点、SERP 端点和社交媒体(TikTok、Instagram 等)采集能力,企业可以直接零代码构建跨平台舆情、销量榜单以及竞对流量变动的监控面板仪表,并通过单一接口聚合全部异构数据。
- 跨生态 AI 聚合模型开发与 A/B 平台测试由于只用一个 API 请求规范就能自由切换超过 60 个大模型,开发者能够针对其应用的具体场景快速横向对比 GPT、Claude 与各类开源模型的反馈质量和耗费资源,无需分别配置庞大且容易失效的多提供商账户。
- 基于大模型工作流(Vibe Coding)的免维护自动化开发开发者只需将平台提供的规范文档交接给 AI 开发框架,便可直接赋能智能体访问外部网络、搜集参考文档、自主排版截取网站界面的能力,实现高度自动化的独立智能助手构建。
- 自媒体与多媒体衍生内容自动生成利用基于统一密钥的文本、图像及 Sora 2 视频端点,自媒体团队可以设计一个“标题数据提取 -> AI生成文案 -> 调用图片/视频接口自动生成配图及动态片段”的闭环自动化流水线体系。
QA
- 使用 YepAPI 必须进行信用卡绑定吗?不需要。注册只需简单验证即可开通服务,并能获得 5 美元的初创额度。平台遵循“用多少,付多少”的原则,绝无隐藏月费及绑卡硬性要求。
- YepAPI 具体的按需扣费标准是怎样的?每个请求功能的价格均是透明和固定的。如大多数普通网页抓取每次消耗 $0.01;复杂的 SEO 数据提取为每次 $0.05;而调用 AI 大模型则参照标准的 Tokens 计算方式计费(如从 $0.001/千 Token 起步)。
- 在平台大面积并发调用时,会有调用速率限制(Rate Limits)吗?常规使用状况下平台并没有硬性速率瓶颈,后台的服务器支持弹性负载扩容。然而面对数千规模的高频率并发场景,建议遵循系统状态反馈及容错延时重新请求的规范。
- 抓取失败的无效网页请求会被计费吗?完全不会。只有当请求成功执行并返回了有效的数据结构时(通常状态码表现为 200),系统才会从用户的储值账户中扣除对应的 Credits。这为开发中的网络调试节省了大量资金。
- 在我的 Cursor 或者现有 AI 智能体项目中应当如何调用 YepAPI?在你的 AI 项目配置文件或者初始指令中,直接引入 YepAPI 的
llms.txt地址,AI 便会自动抓取理解所有的鉴权要求及 JSON 参数格式,并自主生成对接代码或触发相应 Action。